Manga OCR
Speech bubble recognition and text extraction
- Date: March 2022
- Tools: OpenCV, Tesseract OCR, Deepl API, JavaScript, Python
This is a personal project that I worked on to automatically translate manga from Japanese to English. Everything is written in JavaScript so it could be fully client-side so a server wouldn't be needed
Original Image



Speech Bubble Detection
Only keep innermost contours that are a valid size (not too big or small) and somewhat circular in shape
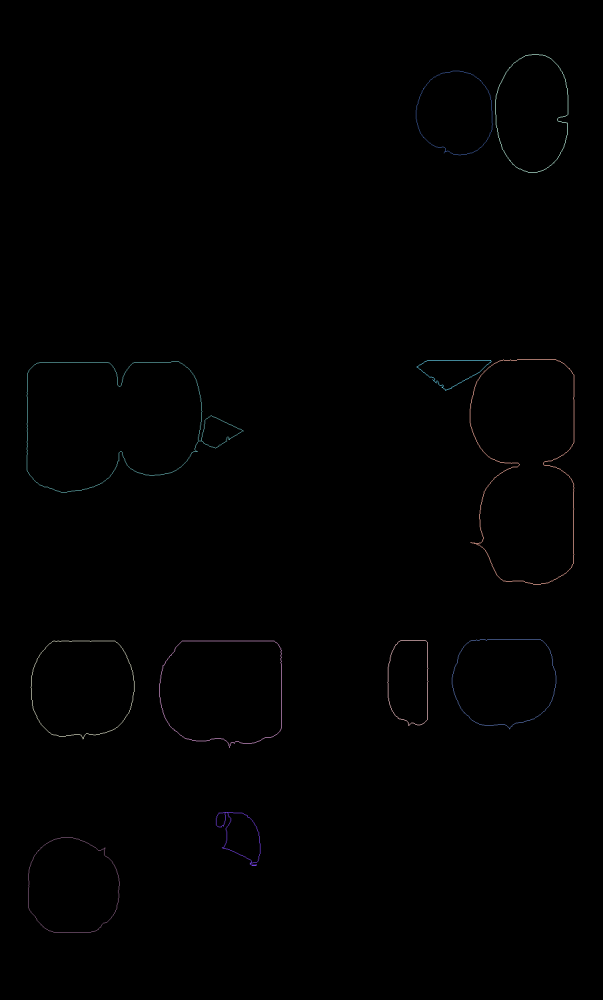
Speech Bubble Extraction
Extract parts of the image inside the speech bubble contours

Furigana Removal
Detect the width of a column of text by counting the number of consecutive columns where not all of the pixels in a column of pixels are white. If the text is too narrow, it's furigana. Change all the pixels in those columns to white to remove furigana.


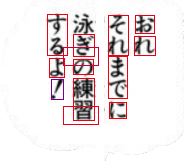

Example Output
